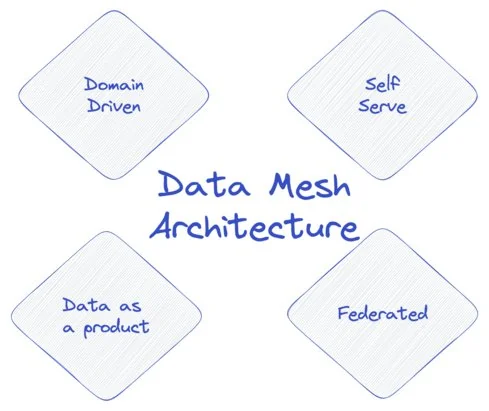
How to create a custom Kedro DataSet
In the following article, i will show how to create a custom dataset for Kedro, an open source Python library for Production-Ready Machine Learning Code.
The custom dataset will be used to read DICOM files and produce image and CSV datasets which are native Kedro datasets.
This article is linked to my article on how to create a kedro project and my project on pneumothorax classifier, you will find more informations on the DICOM dataset there.
To be able to read and extract data from DICOM files, we will use the pydicom library.
DICOMDataSet class
This is the whole custom dataset class we are going to create. I will explain each part. One remark though, we are not going to implement the save part of the dataset class, as it will be not used in our project and it is not very common to write DICOM files in a ML project.
import numpy as np
import pandas as pd
import pydicom
# PIL is the package from Pillow
from PIL import Image
class DICOMDataSet(AbstractDataSet):
def __init__(self, filepath: str):
"""Creates a new instance of DICOMDataSet to load / save image data for given filepath.
Args:
filepath: The location of the DICOM file to load / save data.
"""
# parse the path and protocol (e.g. file, http, s3, etc.)
protocol, path = get_protocol_and_path(filepath)
self._protocol = protocol
self._filepath = PurePosixPath(path)
self._fs = fsspec.filesystem(self._protocol)
def _load(self) -> (pd.DataFrame,np.ndarray):
"""Loads data from the DICOM file.
Returns:
Metadata from the DICOM file as a pandas Dataframe,
Image data as a numpy array
"""
# using get_filepath_str ensures that the protocol and path are appended correctly for different filesystems
load_path = get_filepath_str(self._filepath, self._protocol)
with self._fs.open(load_path) as f:
ds = pydicom.dcmread(f)
df = pd.DataFrame.from_records([(el.name,el.value) for el in ds if el.name not in ['Pixel Data', 'File Meta Information Version']])
df = df.T
df.columns = df.iloc[0]
df = df.iloc[1:]
pixel_array = ds.pixel_array
return (df,pixel_array)
def _save(self, data: np.ndarray) -> None:
"""Saves image data to the specified filepath"""
return None
def _describe(self) -> Dict[str, Any]:
"""Returns a dict that describes the attributes of the dataset.
"""
return dict(
filepath=self._filepath,
protocol=self._protocol
)
init of instance
def __init__(self, filepath: str):
"""Creates a new instance of DICOMDataSet to load / save image data for given filepath.
Args:
filepath: The location of the DICOM file to load / save data.
"""
# parse the path and protocol (e.g. file, http, s3, etc.)
protocol, path = get_protocol_and_path(filepath)
self._protocol = protocol
self._filepath = PurePosixPath(path)
self._fs = fsspec.filesystem(self._protocol)
This part is quite the same for all custom datasets, we store the filepath and the protocol (e.g. file, http, s3, etc.) used to access the dataset.
Load method
def _load(self) -> (pd.DataFrame,np.ndarray):
"""Loads data from the DICOM file.
Returns:
Metadata from the DICOM file as a pandas Dataframe,
Image data as a numpy array
"""
# using get_filepath_str ensures that the protocol and path are appended correctly for different filesystems
load_path = get_filepath_str(self._filepath, self._protocol)
with self._fs.open(load_path) as f:
ds = pydicom.dcmread(f)
df = pd.DataFrame.from_records([(el.name,el.value) for el in ds if el.name not in ['Pixel Data', 'File Meta Information Version']])
df = df.T
df.columns = df.iloc[0]
df = df.iloc[1:]
pixel_array = ds.pixel_array
return (df,pixel_array)
This is definitively the most important part of the class. The load method will be used each time we access the dataset. We will use the pydicom library to read the .dcm files.
ds = pydicom.dcmread(f)
the dcmread method from pydicom library, will be used to read the contents of the dcm file and create a pydicom.dataset.FileDataset class. see pydicom dcmread.
The pydicom.dataset.FileDataset is iterable and we can retrieve each dcm metadata value and the pixel_array that corresponds to the image of xray stored.
df = pd.DataFrame.from_records([(el.name,el.value) for el in ds if el.name not in ['Pixel Data', 'File Meta Information Version']])
df = df.T
df.columns = df.iloc[0]
df = df.iloc[1:]
pixel_array = ds.pixel_array
return (df,pixel_array)
We will retrieve all metadata info in a pandas DataFrame, and the xray image in the form of a numpy.ndarray, and then return them a a tuple.
Describe method
def _describe(self) -> Dict[str, Any]:
"""Returns a dict that describes the attributes of the dataset.
"""
return dict(
filepath=self._filepath,
protocol=self._protocol
)
This method is mandatory and will be called each time we try to execute a .head() method on a kedro dataset. Here we just return a dictionary containing the protocol and the filepath of the dataset on disk.
Add dataset to kedro data catalog
When you add a custom dataset ( same thing for regular ones) you have 2 options : defining only 1 file or a directory. For our dcm files option 2 is the way to go as we have more than 12k dcm files to extract.
Read a single file
To read a single dcm file, just define the type and filepath.
dicom_single:
type: pneumothorax.io.datasets.dicom_dataset.DICOMDataSet
filepath: data/01_raw/dicom-images-train/1.2.276.0.7230010.3.1.4.8323329.300.1517875162.258081.dcm
Read whole directory
To read a whole directory of files, set the type to PartitionedDataSet. Define dataset parameter to the DICOMDataSet type and set path to the directory containing our dcm files. filename_suffix will be used to identify all the dcm files.
dicom_train:
type: PartitionedDataSet
dataset: pneumothorax.io.datasets.dicom_dataset.DICOMDataSet
path: data/01_raw/dicom-images-train
filename_suffix: ".dcm"